Data Processing #
General #
To start of, uman is aware that your data is sensitive and handles it with the utmost care. On this page it is outlined how exactly uman processes and stores your data. The general idea is that uman limits itself to privately store the relevant pieces of your data in order to be able to search on it in a smart and safe way.
When data arrives within the uman Virtual Private Cloud (VPC), it gets processed and stored within the Virtual Private Cloud. Uman does not depend on any 3rd party services for processing and storing data, except for Google Cloud and Elastic Cloud.
In order to retrieve the data securely, we retrieve the refresh and access tokens from our secure token vault and access the information via OAuth 2.0 via HTTPS, as explained in Integrations.
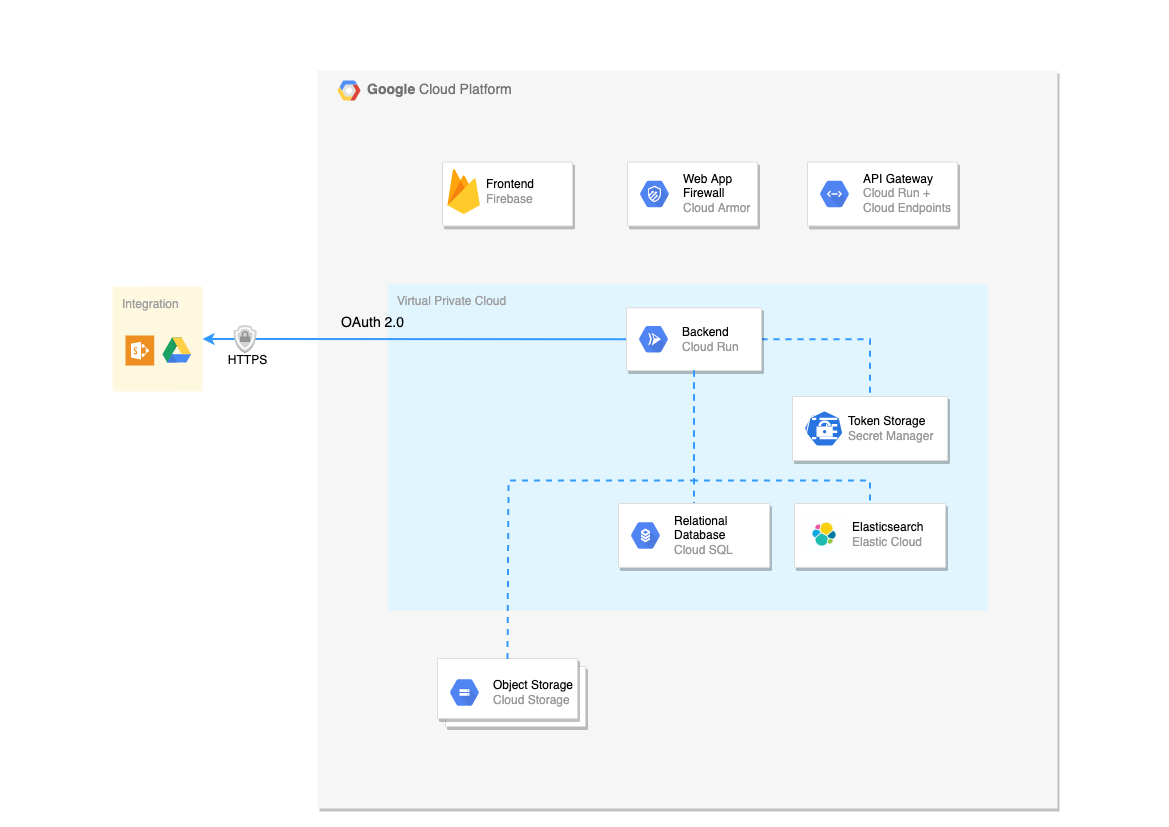
First, the storage layers are outlined in order to describe how specific data is processed and stored into these storage layers.
Storage Layers #
There are three storage layers in which data can be stored, all encrypted at rest:
- Object storage: used for storing blobs, e.g. images of content pages - encrypted via Google-managed keys using AES-256. The object storage is separated per tenant, with separate encryption keys per tenant.
- Relational database: used for storing typical application backend information, e.g. users, permissions - encrypted via Google-managed keys using AES-256. The relational database is by default shared with different tenants.
- Elastic Cloud: used for indexing relevant information in order to be able to search on it - encrypted by Elastic Cloud. The data is stored on a different index per tenant. For more information regarding the Elastic Cloud security, see their security docs.
It is possible to request a single-tenant relational database and elasticsearch instance, with separate encryption keys, at custom pricing.
In the sections below, we go into greater detail on how particular data is processed and stored.
Customer Relationship Management (CRM) data #
In order to make the content easily searchable with the notion of your customers, uman will read the list of customers and store them on uman side in order to cross-match them when we index your content. See Integrations for the list of supported CRM systems.
Data processing #
Upon receival of the list of companies from the CRM integration, that list of companies is matched with our knowledge graph based on domain name (e.g. ’example.com’) as unique identifier. In case the company is not yet existing on uman side, it will be created and enriched via a 3rd party service (based on the domain name that is passed to the service), Clearbit Enrichment API, using the OAuth Protocol. Please note that ownership of this query data is not transferred to Clearbit and kept private for uman. More information on these specific terms can be found in section 4a in Clearbit terms of service. Finally we make a reference between the company identifier from the knowledge graph and your workspace identifier. In this reference we couple the identifiers and store the company name label that was retrieved by the CRM integration.
Data storage #
These references (company domain, label, workspace identifier) are stored in the relational database. They will be used downstream for tagging your content pieces and those tags will be stored in the Elastic Cloud layer.
Data deletion and retention #
Upon termination of the services, all the references of companies to the knowledge graph for your tenant will be removed. The data is retained in automated back-ups until up to sixty days after termination.
Document Management System (DMS) data #
In order to make content searchable, a connection with your document management system is required for retrieving the content which has been selected to index for uman. See Integrations for the list of supported document management systems.
We also leverage the metadata of the content to enhance the search experience. An example is the folder path where the content is hosted as that can contain possible relevant information related to search. Another example is the users that are related to the content (e.g. created by, last modified by).
Data processing #
Upon receival of the content data and metadata we will perform several processing actions within the uman Virtual Private Cloud:
- information extraction (e.g. extract text)
- information enrichment (e.g. assign tags)
- create image per content page
For all of these processing actions we can rely on internal services, the data does not leave the Virtual Private Cloud.
Data storage #
The different pieces of content data are stored separately, each in a storage layer that is fit for purpose. Basically the extracted and enriched information, together with the metadata, is stored in the relational database. A subset of that information, that is relevant to search, is stored in the Elastic Cloud layer as well.
The images of the content pages are stored on the object storage. For the content pages that match a search query, uman will temporarily grant access to these images via signed URLs so that these pages can be rendered in the frontend.
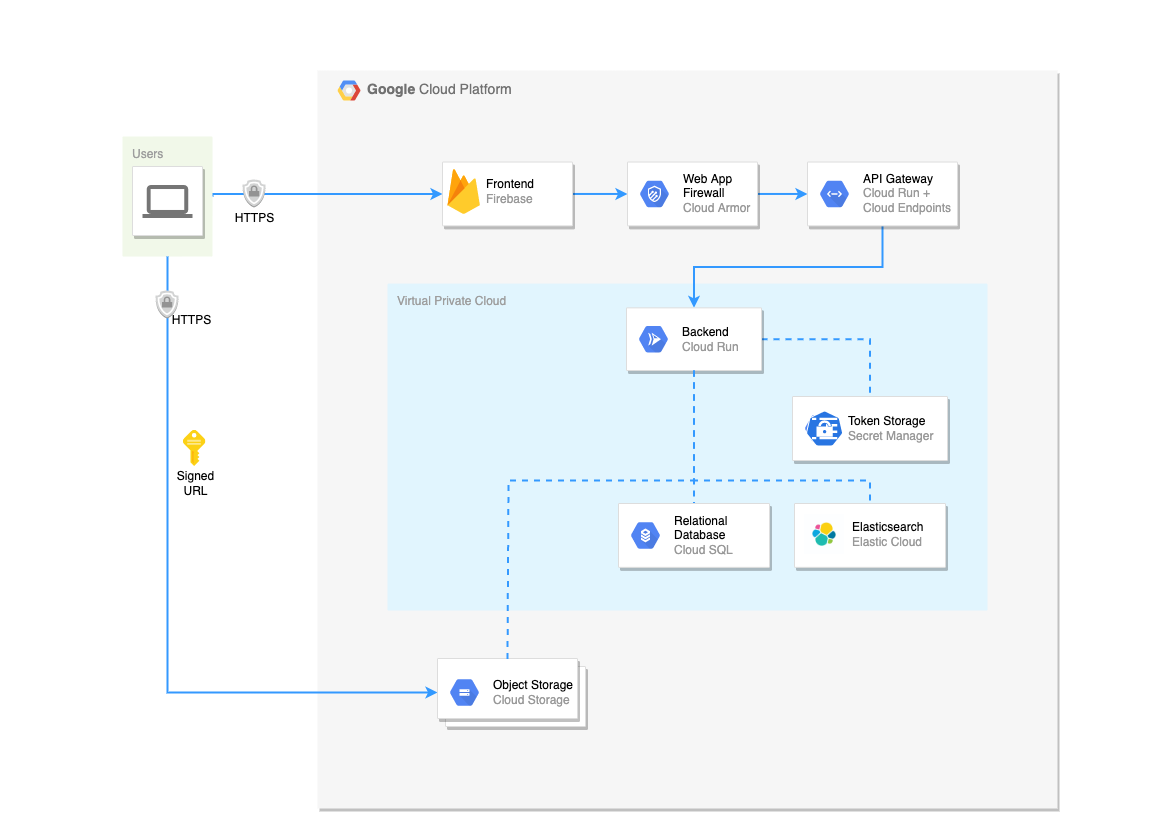
These signed URLs are valid for only a limited time period (30 seconds) and each of them point to an isolated content page only.
Data deletion and retention #
When a previously indexed document is no longer present (e.g. erased, moved to another location, etc) in the document management system, we will remove all related information to this document on our storage layers. At that moment, the document will no longer be searchable on the uman platform. The data is retained in automated back-ups until up to sixty days after the file is no longer present.
